Postgres Locks Summarized
Postgres locking is justifiably complicated, but most devs won’t need to know most of it. This is my attempt to pull out the most important parts out of the main primer on Postgres locks: the Explicit Locking chapter of Postgres docs, and simulate a deadlock myself to understand the gist of it.
There are two main lock types of interest: Table-level and Row-level locks.
Some SQL commands acquire at least a table-level lock, but some (like UPDATE) acquire both types of locks at the same time!
The Main Rule of Locks
Locks exist to adhere to one main rule (already well-described by its name): two concurrent transactions cannot acquire conflicting locks.
Conflicting locks are laid out nicely in the Conflicting Lock Modes table. Here’s the table for table-level locks:
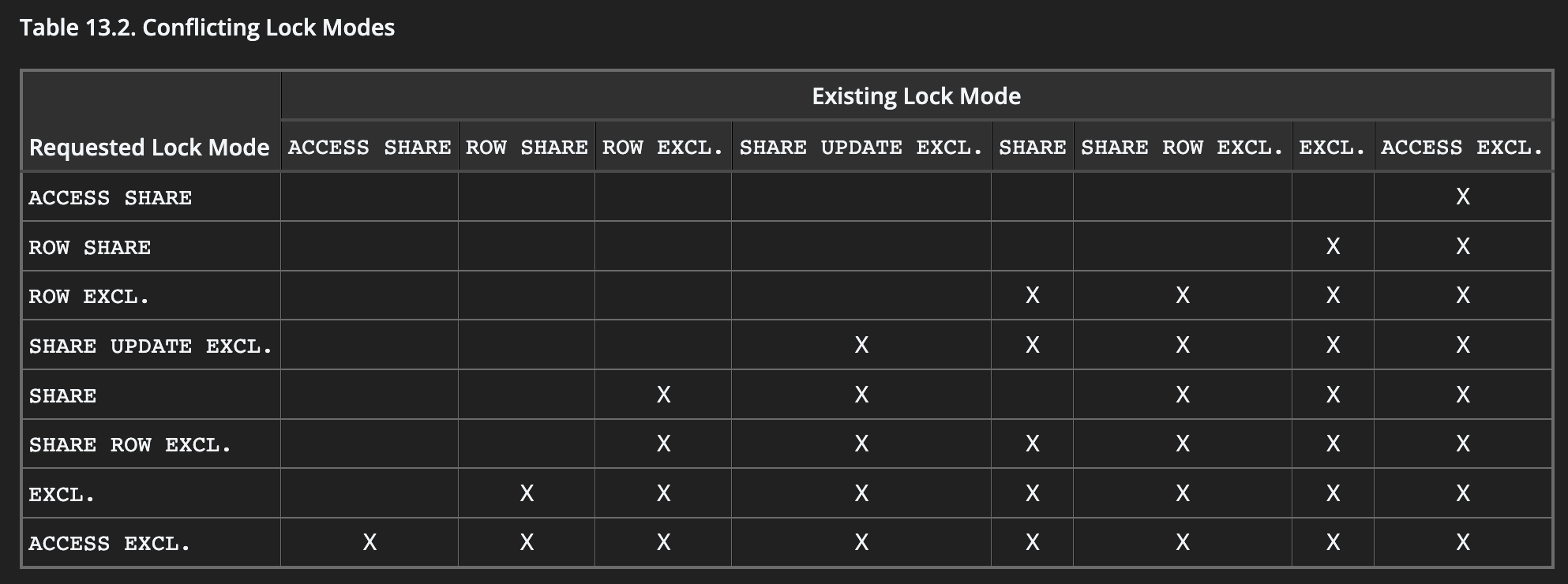
As seen in the table above, the AccessExclusiveLock is the most strict lock. It’s so strict that it even blocks reads (ACCESS SHARE) on the table completely (which the ExclusiveLock allows).
Explicit & Implicit
Locks are acquired implicitly depending on the SQL command. We’ll discuss shortly which locks are automatically acquired by which commands. But, it’s important to know that all locks can be also acquired explicitly using the LOCK command.
Table-level Locks
There are a total of 8 table-level locks, the most common being:
- AccessShareLock - acquired by
SELECT - RowExclusiveLock - acquired by
UPDATE,INSERT, andDELETE - AccessExclusiveLock - the strictest of them all, guarantees that only the current transaction has any sort of read/write access to the table! Acquired by “heavy” commands such as
DROP TABLE,TRUNCATE,REINDEX, etc.
An AccessShareLock doesn’t conflict with itself, which makes sense because we’re all already aware that SELECT commands can run concurrently without any issue. (Postgres wouldn’t be a very popular database if reads were sequential.)
Don’t let the “Row” in RowExclusiveLock confuse you, it’s definitely a table-level lock. It’s also a lock that doesn’t conflict with itself, because transactions should be allowed to concurrently modify data in a table. It’s only an issue if they want to modify the same row, and that’s where row-level locks come into play.
Looking at the conflict modes table, AccessExclusiveLock is the only lock with all X’s lined up. A transaction that acquires this lock on a table will have the whole table to itself!
See 13.3.1. Table-Level Locks for the remaining bunch of locks.
Row-level Locks
Row-level, as per their name, are more granular than table-level locks, because they lock rows. In Postgres terminology, you’ll often hear rows referred to as tuples.
Two important things to note about row-level locks:
- Two different transactions cannot hold conflicting locks on the same row (obviously), but a single transaction can hold multiple conflicting locks on the same row.
- Row-level locks never affect data querying, they only block writers and lockers to the same row. Plain
SELECTcommands are always green-lighted!
The four row-level locks:
FOR UPDATE- Can be explicitly acquired by
SELECT(SELECT … FOR UPDATE) - Implicitly acquired by
DELETE(and a tiny amount ofUPDATEs in special cases) - Strongest lock, conflicts with all other modes
- Can be explicitly acquired by
FOR NO KEY UPDATE- Can be explicitly acquired by
SELECT(SELECT … FOR NO KEY UPDATE) - Implicitly acquired by
UPDATE(almost all of them). - It conflicts with itself (see table), meaning two concurrent transactions can’t
UPDATEthe same row.
- Can be explicitly acquired by
FOR SHARE- explicit locking onlyFOR KEY SHARE- explicit locking only, the weakest lock
And the conflicting modes table:

So what’s with all these modes? When should I use which? Think about them this way:
FOR UPDATE- “I want exclusive write access to this row, and who knows what I’ll do with it, it could even end up completely gone”FOR NO KEY UPDATE- “I’m a bit weaker thanFOR UPDATEin that I want exclusive access but I won’t mess with the key values (meaning I also don’t intend to delete the row).”FOR SHARE- “I don’t want anyone to write to the row, but I also don’t need exclusive access to it, let’s share!”FOR KEY SHARE- “Let’s share the row, also feel free to update the row as long as you don’t update the key values”
Running some experiments
We’ve discussed the theory, but lets run some experiments to solidify our learnings.
This is the table we’ll be using for the experiments:
create table countries (id int primary key, long_name text);
insert into countries (id, long_name) values (1, 'Kosovo'), (2, 'United States');
Two transactions can’t update the same row (FOR NO KEY UPDATE)
Open the first SQL session and run:
begin;
update countries set long_name = 'Kosovo (updated)' where id = 1;
Notice that we leave the transaction hanging (no commit or rollback yet).
In a second SQL session, run:
update countries set long_name = 'Kosovo (updated2)' where id = 1;
You’ll notice that the second SQL transaction hangs indefinitely, waiting for the first transaction to let go of the lock on that row.
What if we try another row?
update countries set long_name = 'United States (updated)' where id = 2;
Runs without any issues, because no lock is held on row ID 2.
Simulating a deadlock
Lets hit an actual deadlock. In session 1, run:
begin;
update countries set long_name = 'Kosovo (updated1)' where id = 1;
In session 2:
begin;
update countries set long_name = 'United States (updated2)' where id = 2;
update countries set long_name = 'Kosovo (updated2)' where id = 1;
/* ^ The order is very important! */
At this point, session 2 should hang, waiting for the first session’s transaction to release the lock on row ID 1.
And then, we deal the final blow by running the below in session 1:
update countries set long_name = 'United States (updated1)' where id = 2;
Postgres will detect the deadlock and throw an error:
SQL Error [40P01]: ERROR: deadlock detected
Detail: Process 4913 waits for ShareLock on transaction 1103; blocked by process 5125.
Process 5125 waits for ShareLock on transaction 1102; blocked by process 4913.
Hint: See server log for query details.
Where: while updating tuple (0,8) in relation "countries"
Two transactions are waiting for each other, causing a deadlock.
TRUNCATE vs UPDATE
A pretty simple one: TRUNCATE will try to acquire an AccessExclusiveLock, but another transaction holds a RowExclusiveLock on the table, causing the TRUNCATE command to hang.
Session 1:
begin;
update countries set long_name = 'Kosovo (updated1)' where id = 1;
Session 2:
truncate table countries;
Session 2 correctly hangs, waiting for the AccessExclusiveLock.
Deep dive
Lets do a deep dive into what’s going on by querying the pg_locks table.
We run a handy query to see the ongoing lock, with process IDs:
select blocked_locks.mode as blocked_mode,
blocked_locks.pid AS blocked_pid,
blocked_activity.usename AS blocked_user,
blocking_locks.pid AS blocking_pid,
blocking_activity.usename AS blocking_user,
blocked_activity.query AS blocked_statement,
blocking_activity.query AS current_statement_in_blocking_process
FROM pg_catalog.pg_locks blocked_locks
JOIN pg_catalog.pg_stat_activity blocked_activity ON blocked_activity.pid = blocked_locks.pid
JOIN pg_catalog.pg_locks blocking_locks
ON blocking_locks.locktype = blocked_locks.locktype
AND blocking_locks.database IS NOT DISTINCT FROM blocked_locks.database
AND blocking_locks.relation IS NOT DISTINCT FROM blocked_locks.relation
AND blocking_locks.page IS NOT DISTINCT FROM blocked_locks.page
AND blocking_locks.tuple IS NOT DISTINCT FROM blocked_locks.tuple
AND blocking_locks.virtualxid IS NOT DISTINCT FROM blocked_locks.virtualxid
AND blocking_locks.transactionid IS NOT DISTINCT FROM blocked_locks.transactionid
AND blocking_locks.classid IS NOT DISTINCT FROM blocked_locks.classid
AND blocking_locks.objid IS NOT DISTINCT FROM blocked_locks.objid
AND blocking_locks.objsubid IS NOT DISTINCT FROM blocked_locks.objsubid
AND blocking_locks.pid != blocked_locks.pid
JOIN pg_catalog.pg_stat_activity blocking_activity ON blocking_activity.pid = blocking_locks.pid
WHERE NOT blocked_locks.granted;
The result we get:
| blocked_mode | blocked_pid | blocked_user | blocking_pid | blocking_user | blocked_statement | current_statement_in_blocking_process |
|---|---|---|---|---|---|---|
| AccessExclusiveLock | 5125 | postgres | 4913 | postgres | truncate table countries | SHOW search_path |
We notice that pid 5125 is the one being blocked by pid 4913. Lets confirm that pid 5125 is the one running the truncate query:
select query from pg_catalog.pg_stat_activity where pid = 5125
Correctly gives us:
| pid | query |
|---|---|
| 5125 | truncate table countries |
Lets go deeper, and find the conflicting locks held on the table:
select relation::regclass, locktype, pid, mode, granted
from pg_locks
where pid in (4913, 5125) and relation = 'countries'::regclass
And we get:
| relation | locktype | pid | mode | granted |
|---|---|---|---|---|
| countries | relation | 5125 | AccessExclusiveLock | false |
| countries | relation | 4913 | RowExclusiveLock | true |
As expected, the first transaction (pid 4913) acquired a RowExclusiveLock on the table, which it was granted (because it was first), whereas the second transaction (pid 5125) has not yet been granted an AccessExclusiveLock to the table!
Row-level locks aren’t as simple
I tried to perform the same deep dive with row-level locks, but pg_locks has some gotchas when it comes to row-level locks.
The row-level locks aren’t shown in the pg_locks view because information on row-level locks are stored on disk, not in memory:
Although tuples are a lockable type of object, information about row-level locks is stored on disk, not in memory, and therefore row-level locks normally do not appear in this view. If a process is waiting for a row-level lock, it will usually appear in the view as waiting for the permanent transaction ID of the current holder of that row lock.
That’s exactly what was going on: I kept seeing locks of type transactionid show up in pg_locks instead of type tuple, and it confused the heck out of me. These links found via Google definitely helped:
- https://www.postgresql.org/message-id/201.1274157039%40sss.pgh.pa.us
- https://dba.stackexchange.com/a/216479
- https://postgrespro.com/blog/pgsql/5968005#:~:text=PostgreSQL stores information,a little later.
Tools I used
The only tool necessary for this was DBeaver, an amazing open source DB management tool that I use almost daily. Highly recommend!
Some DBeaver TILs I encountered while writing this post:
- DBeaver has variables!
- By default, a new connection is opened every time a new editor is opened.
- Connections have types: Development, Test, Production. When “Production” is chosen, auto-commit is off by default